Redis高并发分布式锁的实现
例子
在秒杀活动中,用户在购买前判断库存是否充足,然后购买成功后会减掉库存。简单代码如下:
1 | import redis |
这是正常的扣库存逻辑,但是这只适合在单机环境下运行,一个执行完了下一个再执行,这样不会有问题。但是在有并发的情况下,这种写法会出现严重的问题。
假设在并发环境下,有两个请求同时执行到了上述代码的第4行,这时他们查出来的库存量是一样的,后面继续执行,到最后会发现有两个请求购买成功了,但是库存只减了1,这样就会出现超卖的问题。并发越高这个问题越严重。
使用分布式锁解决
要解决这个问题,就要保证同时只有一个请求处理这段逻辑。在redis中有setnx方法可以用来实现。
setnx说明
格式: setnx key value
将 key 的值设为 value,若给定的 key 已经存在,则 SETNX 不做任何动作
示例
1 | 127.0.0.1:6379[1]> EXISTS job # job这个key不存在 |
第1步完善
根据setnx的规则,将逻辑添加到最开始的代码中,完善一下:
1 | lock_key = 'lock_key' |
主要是根据setnx的结果来判断是否是获取到锁,是就执行减库存的操作,不是则返回网络错误。
第2步完善
当在执行删除key的操作前,程序异常退出了,后面的请求永远不会执行到减库存的逻辑。
这个办法我们可以用try…finally来解决
1 | lock_key = 'lock_key' |
第3步完善
除了程序异常退出,还可能机器宕机,这样异常就捕获不到了,这是就需要给key设置一个过期时间。等到过期时间到后key就会被redis销毁掉,不会影响其他的请求。
1 | lock_key = 'lock_key' |
第4步完善
设置过期时间的代码和设置锁值的代码分开来执行,这个应该使用原子性来执行,在python中,可以使用另一个方法来设置锁值:
1 | conn.set(lock_key, 'lock', nx=True, ex=10) |
用这个方法去替换上述两个分开的操作。
1 | lock_key = 'lock_key' |
第5步完善
在一般情况下,这样的处理逻辑没有问题,但是在有些特殊情况下,例如:
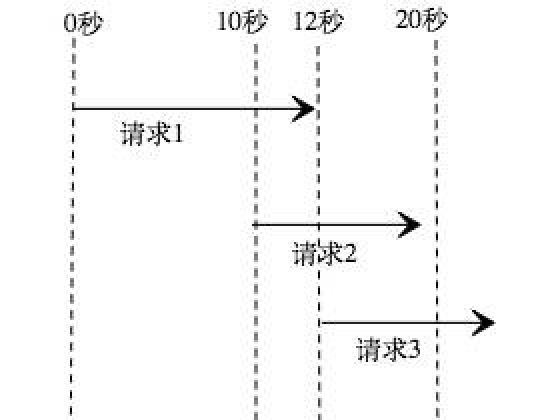
- 当前请求1的处理库存逻辑需要12秒,还没执行完,锁就失效了;
- 请求2获得了锁后,开始处理逻辑,请求2执行了2秒后,请求1处理完毕,删除了锁,但是这个锁是请求2的锁;
- 请求3,不等到请求2释放锁,在第12秒时就可以获得锁;
- 然后请求2会会再把请求3的锁提前释放掉。
- …
这种情况在高并发下就会导致锁失效的情况,虽然代码里面加了锁的判断,但是在实际执行是并没有使用到。
针对这种问题,我们需要对判断要删除的锁是不是自己创建的。
1 | import random |
第6步完善
到上述的阶段,逻辑上没有什么太大的问题,可以在生产环境上运行了,但是有个锁有效期的问题,设置多长时间合适是一个问题。
可以在处理请求的同时再开一个线程在后台执行,这个后台线程的任务就是每个一段时间判断锁有没有过期,如果没有过期,就重新设置锁的有效期。当请求的线程执行完毕后,连带着后台线程一起销毁。